
You run a Python script. Everything works fine. Then suddenly, a strange softout4.v6 error appears and stops your workflow. No clear docs. No direct fix. Just confusion.
This issue is becoming common in data pipelines, automation scripts, and structured output systems. Many developers struggle to understand what softout4.v6 actually means. Some think it is a library. Others treat it like a versioned output format.
In reality, softout4.v6 is tied to structured data handling, version control, and Python-based processing workflows. It plays a key role when working with tools like Pandas, NumPy, or large datasets.
This guide breaks it down in simple terms. You will learn what it is, how it works, and how to fix errors fast.
What is softout4.v6?
Understanding softout4.v6 can feel confusing at first. The term looks technical, but the concept is simple once you break it down. It mainly relates to how systems handle and organize output data in a stable way.
Breaking Down the Term
The name softout4.v6 has two key parts:
- softout4 → refers to a structured output system used in data processing workflows
- v6 → represents version 6, which ensures consistency across updates
This versioning matters. When systems evolve, output formats often change. With softout4 version 6, developers maintain a fixed structure. That prevents unexpected breaks in automation pipelines.
Why softout4.v6 Exists
In many Python-based systems, raw outputs can be messy. Small format changes can break entire workflows.
softout4.v6 solves this by:
- Enforcing consistent data formatting
- Supporting reusable output structures
- Reducing errors in data pipelines
It is commonly used in:
- Python workflows
- ETL processes
- data engineering tasks
In short, softout4.v6 helps developers produce clean, predictable, and reliable outputs.
How softout4.v6 Works in Real Systems
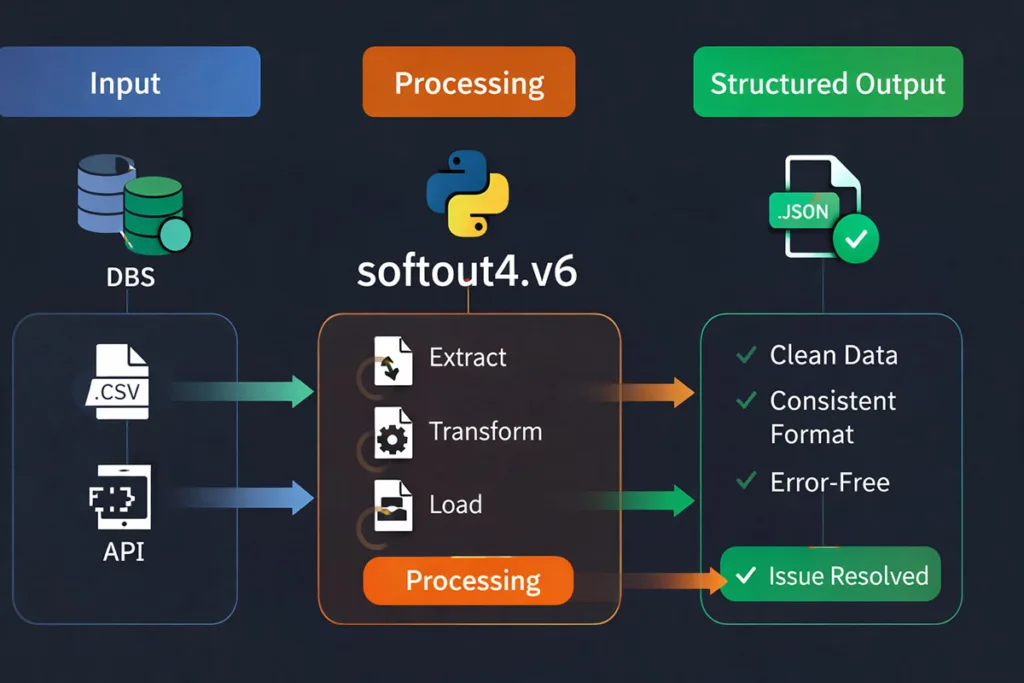
To understand softout4.v6, you need to see it in action. It is not just a concept. It works behind the scenes in real data workflows and automation systems.
Typical Workflow: Input → Processing → Output
In real systems, softout4.v6 follows a simple flow:
- Input → raw data from files, APIs, or databases
- Processing → cleaning, filtering, and transforming data
- Output → structured data in a fixed format
This structure helps maintain consistency. For example, when using Python, data processed through Pandas or NumPy can be exported in a predictable format. That makes downstream systems stable and easier to manage.
Why Versioning Matters
The v6 versioning system plays a critical role. It ensures that output formats do not change unexpectedly.
Without version control:
- Scripts may break
- Data mismatches can occur
With softout4.v6, each update follows a controlled structure. This improves reliability across data pipelines.
Key Benefits in Real Systems
- Ensures data consistency across systems
- Reduces errors in automation workflows
- Supports scalability in large datasets
In practice, this means fewer failures and smoother data handling.
softout4.v6 in Python
Using softout4.v6 in Python becomes much easier once you see how it fits into real workflows. It is often used where structured outputs and stable data handling are required. Developers rely on it when working with large or messy datasets.
How Developers Use softout4.v6 in Python
In most cases, data softout4.v6 python workflows follow a clear pattern. You load data, process it, and export it in a fixed structure.
Typical steps include:
- Load data from CSV, JSON, or APIs
- Clean missing or inconsistent values
- Transform data into usable formats
- Export structured output
This approach is common in automation scripts and data engineering tasks. It helps maintain consistency across multiple systems.
Core Tasks in Python Workflows
When working with softout4.v6, developers usually focus on:
- Data Loading
Import datasets using tools like Pandas - Data Cleaning
Remove errors, duplicates, or null values - Data Transformation
Apply filters, conditions, or calculations
These steps ensure smooth processing, especially in new softout4.v6 python environments.
Integration with Python Libraries
The release softout4.v6 python setups often integrate with:
- Pandas for data manipulation
- NumPy for numerical operations
This combination allows efficient handling of both small and large datasets without breaking workflows.
softout4.v6 Code Examples
Seeing real examples makes everything clearer. Instead of theory, let’s walk through how softout4.v6 python code works in practice. These examples show how developers handle structured data step by step.
Basic Example: Load, Process, Export
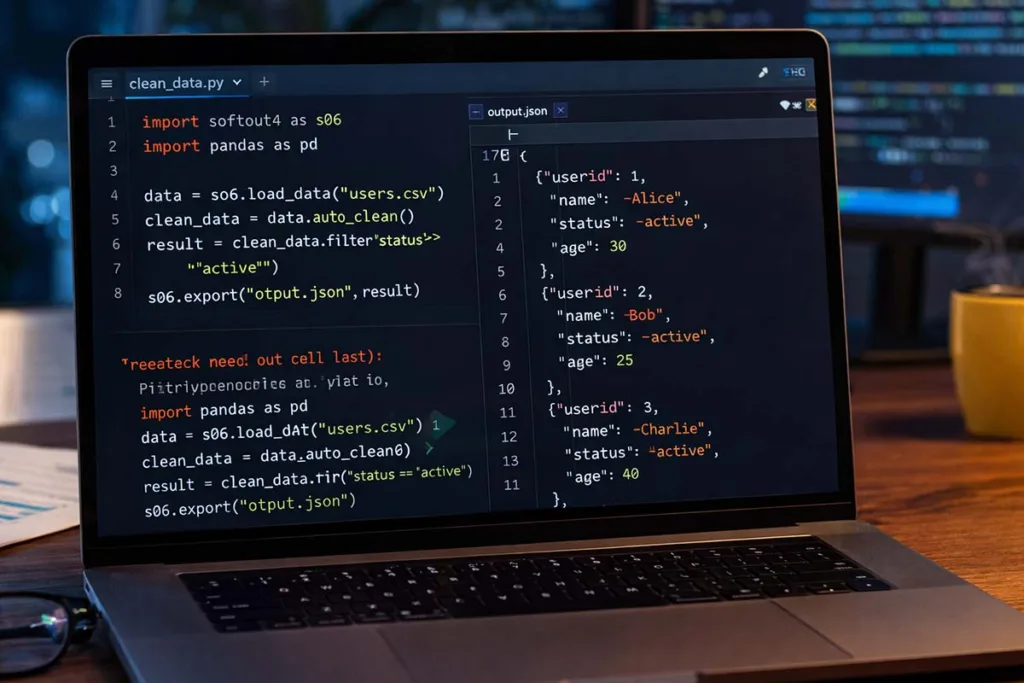
Here is a simple softout4.v6 code workflow:
import softout4 as so6
<> Pyhton
data = so6.load_data("input.json")
cleaned = data.auto_clean()
filtered = cleaned.filter_data("status == 'active'")
filtered.export("output.csv")This example shows a typical flow:
- Load data from a file
- Clean unwanted values
- Filter useful records
- Export structured output
Each step keeps the data consistent. That is the main goal of softout4.v6.
Step-by-Step Explanation
Let’s break it down:
- load_data() → Reads raw data from JSON or CSV
- auto_clean() → Fixes missing or invalid values
- filter_data() → Applies conditions to refine results
- export() → Saves output in a structured format
This flow is common in data pipelines and automation scripts.
Advanced Example: Handling Larger Data
For bigger datasets, developers often add error handling:
<> Python
data = so6.load_data("large_file.csv")
data.auto_clean()
data.export("final_output.csv")
except Exception as e:
print("Processing error:", e)This approach improves stability, especially when working with large datasets and real-time processing systems.
Common softout4.v6 Errors
Even experienced developers run into issues with softout4.v6. Most problems are not complex, but they can stop your workflow instantly. Understanding the root cause helps you fix them faster.
Type Mismatch Error
This is one of the most common softout4.v6 error cases. It happens when data types do not match expected formats.
For example:
- Text values used in numeric operations
- Mixed data inside the same column
This often appears during data processing in Python workflows.
Version Conflict Error
The the error softout4.v6 can also occur due to version mismatches.
Common causes include:
- Different scripts using different output versions
- Outdated configurations in automation systems
This breaks compatibility across data pipelines.
Permission Error
Sometimes, the system cannot write or access files.
This may happen when:
- Folder permissions are restricted
- The script lacks proper access rights
It is common in server environments or shared systems.
Memory or Performance Issues
Large datasets can trigger crashes. This is common when handling high-volume data without proper optimization.
Without efficient handling, structured output systems may slow down or fail unexpectedly.
How to Fix softout4.v6 Errors Fast
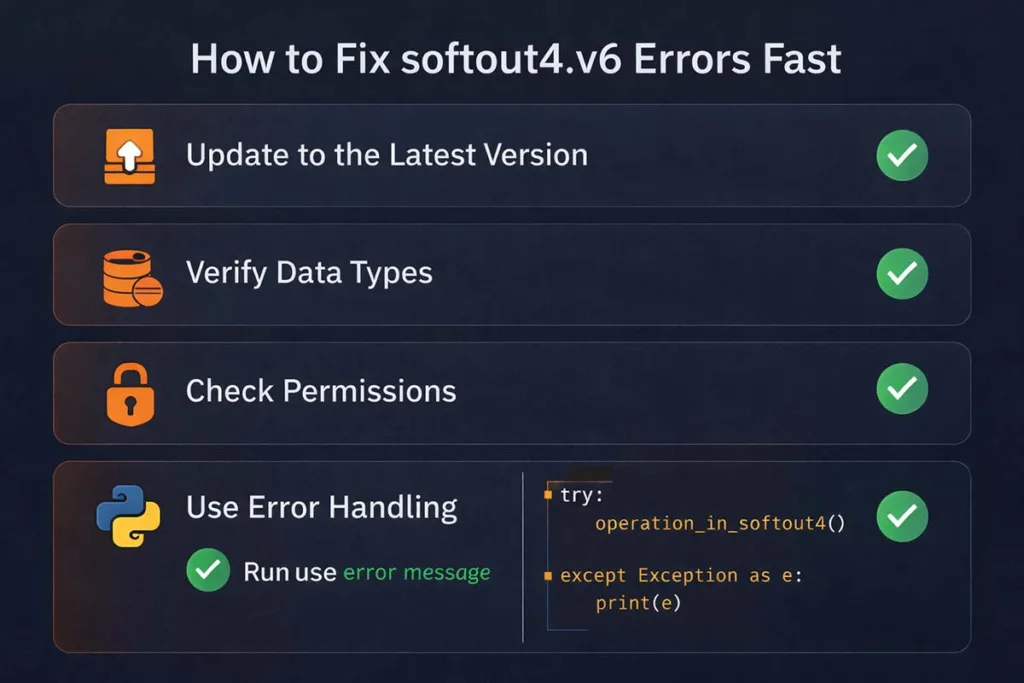
Fixing softout4.v6 errors does not need to be complicated. Most issues come from small mistakes in data handling or setup. Once you follow a clear process, you can resolve them quickly and keep your workflow stable.
1. Update to the Latest Version
Start with the basics. Many errors come from outdated setups.
- Run updates using pip or your package manager
- Ensure all scripts use the same softout4 version 6
This reduces compatibility issues in Python environments.
2. Validate Data Types Before Processing
Incorrect data formats often trigger failures.
- Check for mixed values in columns
- Ensure numeric fields contain only numbers
- Clean data using Pandas functions
This step is critical in data pipelines.
3. Check File Permissions and Access
Permission issues can silently break execution.
- Verify read/write access for files
- Run scripts with proper privileges
- Check directory paths in your system
This is common in server-based automation systems.
4. Use Streaming for Large Datasets
Large files can cause crashes or slow performance.
- Process data in smaller chunks
- Avoid loading full datasets into memory
This improves stability in high-volume data processing.
5. Ensure Version Compatibility Across Systems
Mismatched versions often cause hidden errors.
- Align all scripts to the same version
- Avoid mixing old and new formats
Consistency is key for reliable structured output systems.
Real Use Cases of softout4.v6
Understanding where softout4.v6 is used helps you see its real value. It is not limited to theory. Developers apply it daily in different data-driven environments and workflows.
Data Engineering Pipelines
In ETL pipelines, softout4.v6 ensures clean and consistent output.
- Extract data from multiple sources
- Transform it into structured formats
- Load it into databases
This improves reliability in large-scale data processing.
Automation Scripts
Many Python automation scripts depend on stable outputs.
- Scheduled reports
- Batch processing jobs
Using structured output systems prevents unexpected failures during execution.
Machine Learning Workflows
Before training models, data must be clean and structured.
softout4.v6 helps:
- Prepare datasets
- Remove inconsistencies
- Maintain format consistency
This is essential for accurate machine learning models.
Real-Time Data Systems
In streaming systems, data flows continuously.
- Logs
- API responses
With softout4.v6, outputs remain stable even under high-volume data loads.
Best Practices for Using softout4.v6
Using softout4.v6 the right way can save you hours of debugging. Small improvements in your workflow can prevent major issues later. These best practices help you keep your system stable and efficient.
Keep Output Structure Consistent
Always maintain a fixed format for your outputs.
- Avoid changing field names frequently
- Keep schema stable across versions
This ensures smooth flow in data pipelines and automation systems.
Use Proper Version Control
Versioning is not optional. It is essential.
- Stick to the same softout4 version 6 across projects
- Document any changes clearly
This prevents conflicts in multi-system environments.
Validate Data Before Export
Clean data reduces errors.
- Check for null values
- Ensure correct data types
Tools like Pandas help simplify this process.
Log Errors Instead of Stopping Execution
Do not let one error break everything.
- Use logging for tracking issues
- Continue processing valid data
This improves reliability in high-volume data processing systems.
FAQs Section
Many users still have quick questions about softout4.v6. Here are clear answers to the most common ones.
1. Is softout4.v6 a Python library?
Not exactly. softout4.v6 is more of a structured output system or format used in Python workflows. Some tools or scripts may implement it like a library, but it is not a standard package like Pandas.
2. Why am I getting a softout4.v6 error?
Most errors happen due to:
- incorrect data types
- version mismatch
- invalid file permissions
These issues often appear in data pipelines or automation scripts.
3. How do I fix softout4.v6 errors quickly?
Start simple. Update your version, validate your data, and check permissions. In many cases, this resolves the issue without deep debugging.
4. Can beginners use softout4.v6?
Yes, but basic knowledge of Python and data handling helps. With simple examples, beginners can use it effectively.
Conclusion
Working with softout4.v6 becomes much easier once you understand its purpose. It is not just about code. It is about creating stable and predictable structured output systems.
In real-world Python workflows, small data issues can break entire processes. That is why version control, clean data, and proper handling matter. Tools like Pandas and NumPy make this process smoother when used correctly. If you focus on consistency and validation, most softout4.v6 errors can be avoided. Keep your workflow simple. Stick to best practices. Over time, you will build more reliable and scalable data pipelines without unnecessary failures.
For more insightful articles, please visit Techroyall.

